Uygulama Monitoring: Prometheus, Grafana ve Alerting
z
zafer ak
Yazar
27 Ekim 2025
13 dakika okuma
1212 görüntülenme
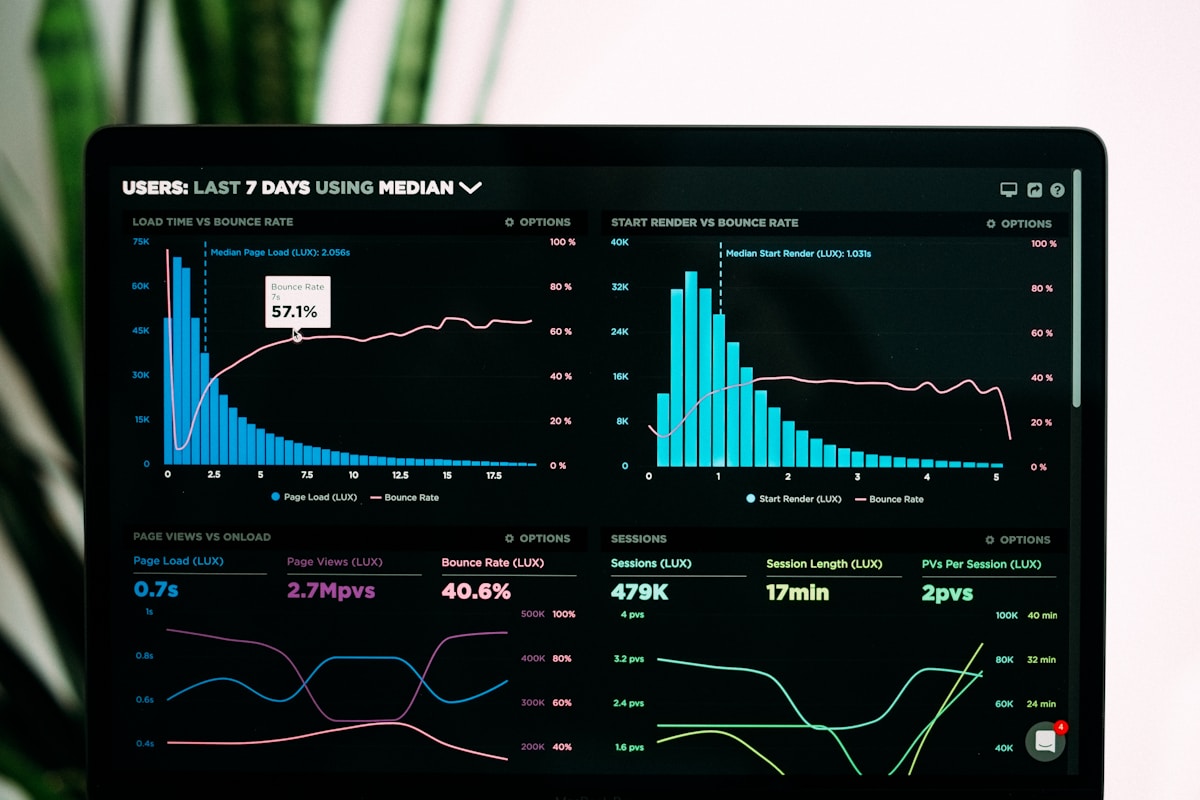
Production uygulamalarınızı izleyin. Metrics collection, dashboard oluşturma ve akıllı alerting.
Monitoring Neden Kritik?
Monitoring olmadan production'da kör uçuş yaparsınız. Sorunları kullanıcılardan önce tespit etmek için kapsamlı izleme şarttır.
Monitoring Stack
- Prometheus: Metrics collection ve storage
- Grafana: Visualization ve dashboards
- AlertManager: Alert routing ve notification
- Loki: Log aggregation
Prometheus Kurulumu
# docker-compose.yml
services:
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.retention.time=15d"
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=secret
volumes:
prometheus_data:
grafana_data:prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
rule_files:
- "alerts/*.yml"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "laravel"
static_configs:
- targets: ["app:9000"]
metrics_path: /metrics
- job_name: "nginx"
static_configs:
- targets: ["nginx-exporter:9113"]
- job_name: "mysql"
static_configs:
- targets: ["mysql-exporter:9104"]Laravel Metrics
// composer require spatie/laravel-prometheus
// routes/web.php
Route::get("/metrics", function () {
return response(Prometheus::export(), 200, [
"Content-Type" => "text/plain; version=0.0.4"
]);
})->middleware("auth.basic");
// app/Providers/PrometheusServiceProvider.php
public function boot()
{
// Request duration histogram
Prometheus::histogram("http_request_duration_seconds")
->labels(["method", "route", "status"])
->observe(microtime(true) - LARAVEL_START);
// Active users gauge
Prometheus::gauge("active_users_total")
->set(User::where("last_seen_at", ">", now()->subMinutes(5))->count());
// Queue jobs counter
Prometheus::counter("queue_jobs_total")
->labels(["queue", "status"])
->increment();
}Alert Rules
# alerts/app.yml
groups:
- name: application
rules:
- alert: HighErrorRate
expr: |
sum(rate(http_requests_total{status=~"5.."}[5m]))
/ sum(rate(http_requests_total[5m])) > 0.05
for: 5m
labels:
severity: critical
annotations:
summary: "High error rate detected"
description: "Error rate is {{ $value | humanizePercentage }}"
- alert: SlowResponseTime
expr: |
histogram_quantile(0.95,
rate(http_request_duration_seconds_bucket[5m])
) > 2
for: 10m
labels:
severity: warning
annotations:
summary: "Slow response times"
description: "95th percentile latency is {{ $value }}s"
- alert: HighMemoryUsage
expr: |
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)
/ node_memory_MemTotal_bytes > 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "High memory usage"AlertManager Config
# alertmanager.yml
global:
slack_api_url: "https://hooks.slack.com/services/xxx"
route:
receiver: "slack-notifications"
group_by: ["alertname", "severity"]
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
routes:
- match:
severity: critical
receiver: "pagerduty"
- match:
severity: warning
receiver: "slack-notifications"
receivers:
- name: "slack-notifications"
slack_configs:
- channel: "#alerts"
title: "{{ .GroupLabels.alertname }}"
text: "{{ .CommonAnnotations.description }}"
- name: "pagerduty"
pagerduty_configs:
- service_key: "xxx"Grafana Dashboard
Önemli paneller:
- Request rate (RPM)
- Error rate percentage
- Response time (p50, p95, p99)
- CPU ve memory kullanımı
- Database query performansı
- Queue backlog
Sonuç
Monitoring, production sistemlerinin vazgeçilmez parçasıdır. Prometheus + Grafana kombinasyonu ile hem metriklerinizi izleyin hem de proaktif alerting kurun.


